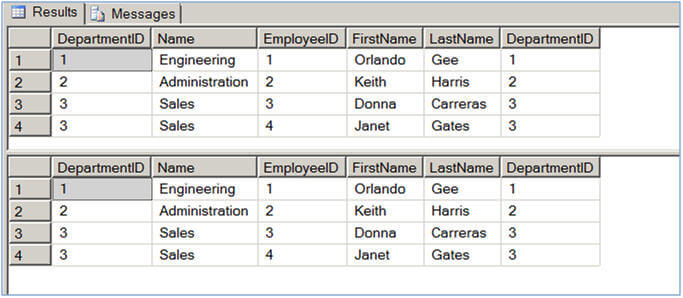
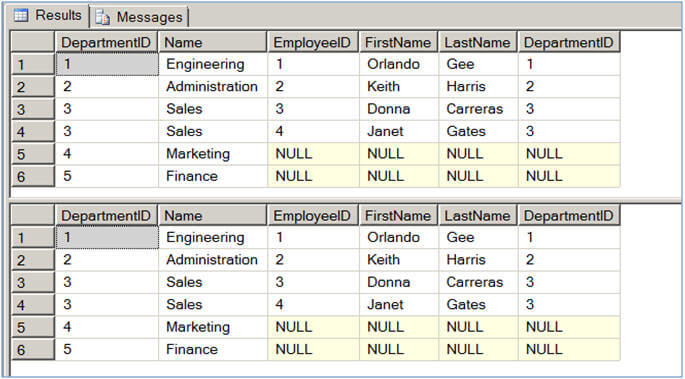
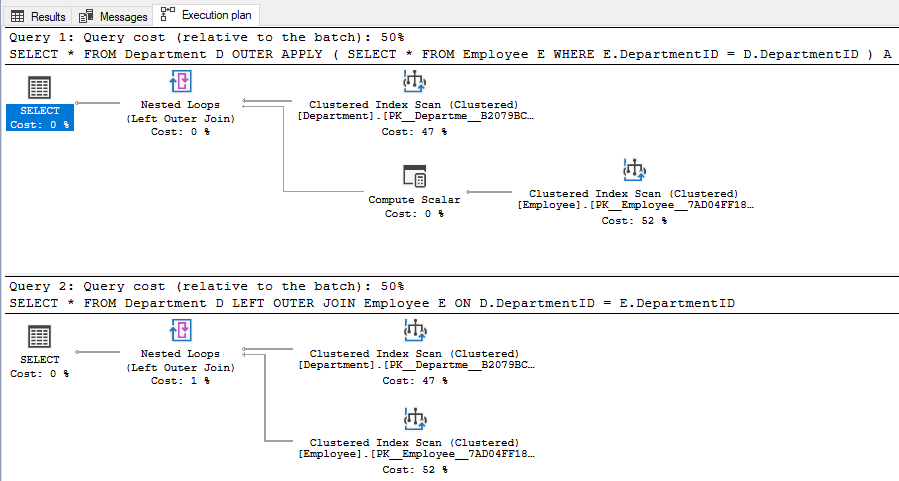
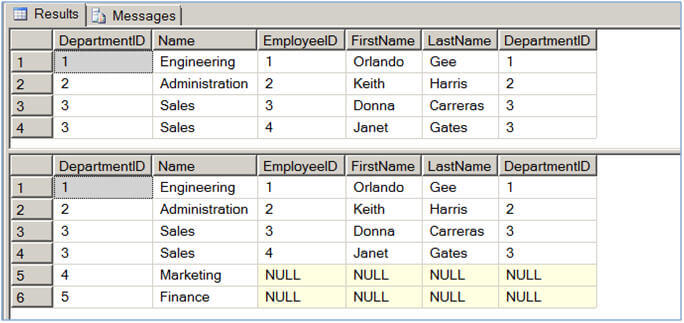
Hints are options or strategies specified for enforcement by the SQL Server query processor on SELECT, INSERT, UPDATE, or DELETE statements. The hints override any execution plan the query optimizer might select for a query.
Caution: Because the SQL Server query optimizer typically selects the best execution plan for a query, we recommend that <join_hint>, <query_hint>, and <table_hint> be used only as a last resort by experienced developers and database administrators.
Join Hints
Join hints specify that the query optimizer enforce a join strategy between two tables in SQL Server 2019
Applies to:
Delete, Update, Select
Syntax:
<join_hint> ::=
{ LOOP | HASH | MERGE | REMOTE }
Arguments
LOOP | HASH | MERGE
Specifies that the join in the query should use looping, hashing, or merging. Using LOOP |HASH | MERGE JOIN enforces a particular join between two tables. LOOP cannot be specified together with RIGHT or FULL as a join type. For more information, see
Joins.
REMOTE
Specifies that the join operation is performed on the site of the right table. This is useful when the left table is a local table and the right table is a remote table. REMOTE should be used only when the left table has fewer rows than the right table.
If the right table is local, the join is performed locally. If both tables are remote but from different data sources, REMOTE causes the join to be performed on the site of the right table. If both tables are remote tables from the same data source, REMOTE is not required.
REMOTE cannot be used when one of the values being compared in the join predicate is cast to a different collation using the COLLATE clause.
REMOTE can be used only for INNER JOIN operations.
Join hints are specified in the FROM clause of a query. Join hints enforce a join strategy between two tables. If a join hint is specified for any two tables, the query optimizer automatically enforces the join order for all joined tables in the query, based on the position of the ON keywords. When a CROSS JOIN is used without the ON clause, parentheses can be used to indicate the join order.
Examples
A. Using HASH
The following example specifies that the JOIN operation in the query is performed by a HASH join. The example uses the AdventureWorks2012 database.
SELECT p.Name, pr.ProductReviewID
FROM Production.Product AS p
LEFT OUTER HASH JOIN Production.ProductReview AS pr
ON p.ProductID = pr.ProductID
ORDER BY ProductReviewID DESC;
B. Using LOOP
The following example specifies that the JOIN operation in the query is performed by a LOOP join. The example uses the AdventureWorks2012 database.
DELETE FROM Sales.SalesPersonQuotaHistory
FROM Sales.SalesPersonQuotaHistory AS spqh
INNER LOOP JOIN Sales.SalesPerson AS sp
ON spqh.SalesPersonID = sp.SalesPersonID
WHERE sp.SalesYTD > 2500000.00;
GO
C. Using MERGE
The following example specifies that the JOIN operation in the query is performed by a MERGE join. The example uses the AdventureWorks2012 database.
SELECT poh.PurchaseOrderID, poh.OrderDate, pod.ProductID, pod.DueDate, poh.VendorID
FROM Purchasing.PurchaseOrderHeader AS poh
INNER MERGE JOIN Purchasing.PurchaseOrderDetail AS pod
ON poh.PurchaseOrderID = pod.PurchaseOrderID;
GO
Query Hints
Query hints specify that the indicated hints should be used throughout the query. They affect all operators in the statement. If UNION is involved in the main query, only the last query involving a UNION operation can have the OPTION clause. Query hints are specified as part of the
OPTION clause. Error 8622 occurs if one or more query hints cause the Query Optimizer not to generate a valid plan.
Applies to: Delete, Update, Insert, Select, Merge
Arguments
{ HASH | ORDER } GROUP
Specifies that aggregations that the query's GROUP BY or DISTINCT clause describes should use hashing or ordering.
{ MERGE | HASH | CONCAT } UNION
Specifies that all UNION operations are run by merging, hashing, or concatenating UNION sets. If more than one UNION hint is specified, the Query Optimizer selects the least expensive strategy from those hints specified.
{ LOOP | MERGE | HASH } JOIN
Specifies all join operations are performed by LOOP JOIN, MERGE JOIN, or HASH JOIN in the whole query. If you specify more than one join hint, the optimizer selects the least expensive join strategy from the allowed ones.
If you specify a join hint in the same query's FROM clause for a specific table pair, this join hint takes precedence in the joining of the two tables. The query hints, though, must still be honored. The join hint for the pair of tables may only restrict the selection of allowed join methods in the query hint. For more information, see
Join Hints (Transact-SQL).
EXPAND VIEWS
Specifies the indexed views are expanded. Also specifies the Query Optimizer won't consider any indexed view as a replacement for any query part. A view is expanded when the view definition replaces the view name in the query text.
This query hint virtually disallows direct use of indexed views and indexes on indexed views in the query plan.
The indexed view remains condensed if there's a direct reference to the view in the query's SELECT part. The view also remains condensed if you specify WITH (NOEXPAND) or WITH (NOEXPAND, INDEX(index_value_ [
,...n ] ) ). For more information about the query hint NOEXPAND, see
Using NOEXPAND.
The hint only affects the views in the statements' SELECT part, including those views in INSERT, UPDATE, MERGE, and DELETE statements.
FAST number_rows
Specifies that the query is optimized for fast retrieval of the first number_rows. This result is a nonnegative integer. After the first number_rows are returned, the query continues execution and produces its full result set.
FORCE ORDER
Specifies that the join order indicated by the query syntax is preserved during query optimization. Using FORCE ORDER doesn't affect possible role reversal behavior of the Query Optimizer.
Table Hints
Table hints override the default behavior of the Query Optimizer for the duration of the data manipulation language (DML) statement by specifying a locking method, one or more indexes, a query-processing operation such as a table scan or index seek, or other options. Table hints are specified in the FROM clause of the DML statement and affect only the table or view referenced in that clause.
KEEPDEFAULTS
Is applicable only in an INSERT statement when the BULK option is used with
OPENROWSET.
Specifies insertion of a table column's default value, if any, instead of NULL when the data record lacks a value for the column.
FORCESEEK [ (index_value(index_column_name [ ,... n ] )) ]
Specifies that the query optimizer use only an index seek operation as the access path to the data in the table or view.
Using a Table Hint as a Query Hint
Table hints can also be specified as a query hint by using the OPTION (TABLE HINT) clause. We recommend using a table hint as a query hint only in the context of a
plan guide. For ad-hoc queries, specify these hints only as table hints. For more information, see
Query Hints (Transact-SQL).
Permissions
The KEEPIDENTITY, IGNORE_CONSTRAINTS, and IGNORE_TRIGGERS hints require ALTER permissions on the table.
Examples
A. Using the TABLOCK hint to specify a locking method
The following example specifies that a shared lock is taken on the Production.Product table in the AdventureWorks2012 database and is held until the end of the UPDATE statement.
UPDATE Production.Product
WITH (TABLOCK)
SET ListPrice = ListPrice * 1.10
WHERE ProductNumber LIKE 'BK-%';
GO
B. Using the FORCESEEK hint to specify an index seek operation
The following example uses the FORCESEEK hint without specifying an index to force the query optimizer to perform an index seek operation on the Sales.SalesOrderDetail table in the AdventureWorks2012 database.
SELECT *
FROM Sales.SalesOrderHeader AS h
INNER JOIN Sales.SalesOrderDetail AS d WITH (FORCESEEK)
ON h.SalesOrderID = d.SalesOrderID
WHERE h.TotalDue > 100
AND (d.OrderQty > 5 OR d.LineTotal < 1000.00);
GO