 Normalization and denormalization are the methods used in databases. The terms are differentiable where Normalization is a technique of minimizing the insertion, deletion and update anomalies through eliminating the redundant data. On the other hand, Denormalization is the inverse process of normalization where the redundancy is added to the data to improve the performance of the specific application and data integrity.
Normalization and denormalization are the methods used in databases. The terms are differentiable where Normalization is a technique of minimizing the insertion, deletion and update anomalies through eliminating the redundant data. On the other hand, Denormalization is the inverse process of normalization where the redundancy is added to the data to improve the performance of the specific application and data integrity.Normalization prevents the disk space wastage by minimizing or eliminating the redundancy.
Comparison Chart
| Basis for comparison | Normalization | Denormalization |
|---|---|---|
| Basic | Normalization is the process of creating a set schema to store non-redundant and consistent data. | Denormalization is the process of combining the data so that it can be queried speedily. |
| Purpose | To reduce the data redundancy and inconsistency. | To achieve the faster execution of the queries through introducing redundancy. |
| Used in | OLTP system, where the emphasize is on making the insert, delete and update anomalies faster and storing the quality data. | OLAP system, where the emphasis is on making the search and analysis faster. |
| Data integrity | Maintained | May not retain |
| Redundancy | Eliminated | Added |
| Number of tables | Increases | Decreases |
| Disk space | Optimized usage | Wastage |
Definition of Normalization
Normalization is the method of arranging the data in the database efficiently. It involves constructing tables and setting up relationships between those tables according to some certain rules. The redundancy and inconsistent dependency can be removed using these rules in order to make it more flexible.
Redundant data wastes disk space, increases data inconsistency and slows down the DML queries. If the same data is present in more than one place and any updation is committed on that data, then the change must be reflected in all locations. Inconsistent data can make data searching and access harder by losing the path to it.
There are various reasons behind performing the normalization such as to avoid redundancy, updating anomalies, unnecessary coding, keeping the data into the form that can accommodate change more easily and accurately and to enforce the data constraint.
Normalization includes the analysis of functional dependencies between attributes. The relations (tables) are decomposed with anomalies to generate relations with a structure. It helps in deciding which attributes should be grouped in a relation.
The normalization is basically based on the concepts of normal forms. A relation table is said to be in a normal form if it fulfils a certain set of constraints. There are 6 defined normal forms: 1NF, 2NF, 3NF, BCNF, 4NF and 5NF. Normalization should eliminate the redundancy but not at the cost of integrity.
Definition of Denormalization
Denormalization is the inverse process of normalization, where the normalized schema is converted into a schema which has redundant information. The performance is improved by using redundancy and keeping the redundant data consistent. The reason for performing denormalization is the overheads produced in query processor by an over-normalized structure.
Denormalization can also be defined as the method of storing the join of superior normal form relations as a base relation, which is in a lower normal form. It reduces the number of tables, and complicated table joins because a higher number of joins can slow down the process. There are various denormalization techniques such as: Storing derivable values, pre-joining tables, hard-coded values and keeping details with master, etc.
Here the denormalization approach, emphasizes on the concept that by placing all the data in one place, could eliminate the need of searching those multiple files to collect this data. The basic strategy is followed in denormalization is, where the most ruling process is selected to examine those modifications that will ultimately improve the performance. And the most basic alteration is that adding multiple attributes to the existing table to reduce the number of joins.
Key Differences Between Normalization and Denormalization
- Normalization is the technique of dividing the data into multiple tables to reduce data redundancy and inconsistency and to achieve data integrity. On the other hand, Denormalization is the technique of combining the data into a single table to make data retrieval faster.
- Normalization is used in OLTP system, which emphasizes on making the insert, delete and update anomalies faster. As against, Denormalization is used in OLAP system, which emphasizes on making the search and analysis faster.
- Data integrity is maintained in normalization process while in denormalization data integrity harder to retain.
- Redundant data is eliminated when normalization is performed whereas denormalization increases the redundant data.
- Normalization increases the number of tables and joins. In contrast, denormalization reduces the number of tables and join.
- Disk space is wasted in denormalization because same data is stored in different places. On the contrary, disk space is optimized in a normalized table.
Conclusion
Normalization and denormalization are useful according to the situation. Normalization is used when the faster insertion, deletion and update anomalies, and data consistency are necessarily required. On the other hand, Denormalization is used when the faster search is more important and to optimize the read performance. It also lessens the overheads created by over-normalized data or complicated table joins.
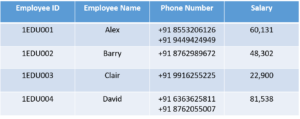
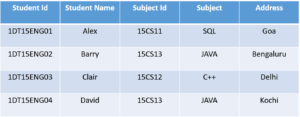
1st Normal Form (1NF)
In this Normal Form, we tackle the problem of atomicity. Here atomicity means values in the table should not be further divided. In simple terms, a single cell cannot hold multiple values. If a table contains a composite or multi-valued attribute, it violates the First Normal Form.
In the above table, we can clearly see that the
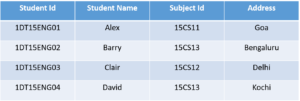
Phone Number column has two values. Thus it violated the 1st NF. Now if we apply the 1st NF to the above table we get the below table as the result.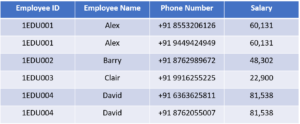
By this, we have achieved atomicity and also each and every column have unique values.
2nd Normal Form (2NF)
The first condition in the 2nd NF is that the table has to be in 1st NF. The table also should not contain partial dependency. Here partial dependency means the proper subset of candidate key determines a non-prime attribute. To understand in a better way lets look at the below example.
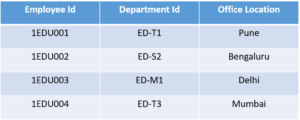
Consider the table
This table has a composite primary key
Emplyoee ID, Department ID. The non-key attribute is Office Location. In this case, Office Location only depends on Department ID, which is only part of the primary key. Therefore, this table does not satisfy the second Normal Form.
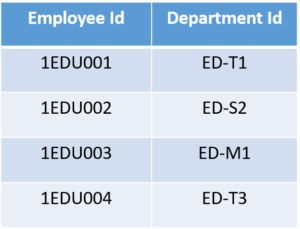
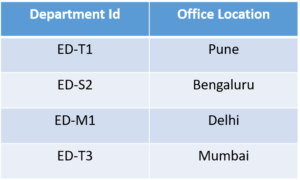
To bring this table to Second Normal Form, we need to break the table into two parts. Which will give us the below tables:
As you can see we have removed the partial functional dependency that we initially had. Now, in the table, the column
Office Location is fully dependent on the primary key of that table, which is Department ID.
Now that we have learnt 1st and 2nd normal forms lets head to the next part of this Normalization in SQL article.
3rd Normal Form (3NF)
The same rule applies as before i.e, the table has to be in 2NF before proceeding to 3NF. The other condition is there should be no transitive dependency for non-prime attributes. That means non-prime attributes (which doesn’t form a candidate key) should not be dependent on other non-prime attributes in a given table. So a transitive dependency is a functional dependency in which X → Z (X determines Z) indirectly, by virtue of X → Y and Y → Z (where it is not the case that Y → X)
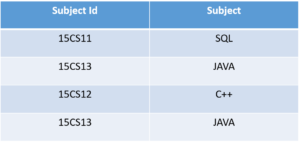
Let’s understand this more clearly with the help of an example:
In the above table,
Student ID determines Subject ID, and Subject ID determines Subject. Therefore, Student ID determines Subject via Subject ID. This implies that we have a transitive functional dependency, and this structure does not satisfy the third normal form.
Now in order to achieve third normal form, we need to divide the table as shown below:
As you can see from the above tables all the non-key attributes are now fully functional dependent only on the primary key. In the first table, columns
Student Name, Subject ID and Address are only dependent on Student ID. In the second table, Subject is only dependent on Subject ID.Boyce Codd Normal Form (BCNF)
This is also known as 3.5 NF. Its the higher version 3NF and was developed by Raymond F. Boyce and Edgar F. Codd to address certain types of anomalies which were not dealt with 3NF.
Before proceeding to BCNF the table has to satisfy 3rd Normal Form.
In BCNF if every functional dependency A → B, then A has to be the Super Key of that particular table.
Consider the below table:
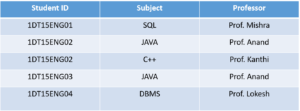
- One student can enrol for multiple subjects.
- There can be multiple professors teaching one subject
- And, For each subject, a professor is assigned to the student
In this table, all the normal forms are satisfied except BCNF. Why?
As you can see
Student ID, and Subject form the primary key, which means the Subject column is a prime attribute. But, there is one more dependency, Professor → Subject.
And while
Subject is a prime attribute, Professor is a non-prime attribute, which is not allowed by BCNF.
Now in order to satisfy the BCNF, we will be dividing the table into two parts. One table will hold
Student ID which already exists and newly created column Professor ID.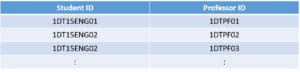
And in the second table, we will have the columns
Professor ID, Professor and Subject.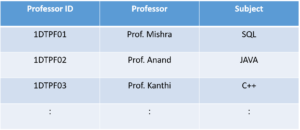
By doing this we are satisfied the Boyce Codd Normal Form.
No comments:
Post a Comment