SQL Server APPLY operator has two variants; CROSS APPLY and OUTER APPLY
- The CROSS APPLY operator returns only those rows from the left table expression (in its final output) if it matches with the right table expression. In other words, the right table expression returns rows for the left table expression match only.
- The OUTER APPLY operator returns all the rows from the left table expression irrespective of its match with the right table expression. For those rows for which there are no corresponding matches in the right table expression, it contains NULL values in columns of the right table expression.
- So you might conclude, the CROSS APPLY is equivalent to an INNER JOIN (or to be more precise its like a CROSS JOIN with a correlated sub-query) with an implicit join condition of 1=1 whereas the OUTER APPLY is equivalent to a LEFT OUTER JOIN.
You might be wondering if the same can be achieved with a regular JOIN clause, so why and when do you use the APPLY operator? Although the same can be achieved with a normal JOIN, the need of APPLY arises if you have a table-valued expression on the right part and in some cases the use of the APPLY operator boosts performance of your query. Let me explain with some examples.
Create Sample Data for CROSS APPLY and OUTER APPLY examples
Script #1 creates a Department table to hold information about departments. Then it creates an Employee table which holds information about the employees. Please note, each employee belongs to a department, hence the Employee table has referential integrity with the Department table.
--Script #1 - Creating some temporary objects to work on... USE [tempdb] GO IF EXISTS (SELECT * FROM sys.objects WHERE OBJECT_ID = OBJECT_ID(N'[Employee]') AND type IN (N'U')) BEGIN DROP TABLE [Employee] END GO IF EXISTS (SELECT * FROM sys.objects WHERE OBJECT_ID = OBJECT_ID(N'[Department]') AND type IN (N'U')) BEGIN DROP TABLE [Department] END CREATE TABLE [Department]( [DepartmentID] [int] NOT NULL PRIMARY KEY, [Name] VARCHAR(250) NOT NULL, ) ON [PRIMARY] INSERT [Department] ([DepartmentID], [Name]) VALUES (1, N'Engineering') INSERT [Department] ([DepartmentID], [Name]) VALUES (2, N'Administration') INSERT [Department] ([DepartmentID], [Name]) VALUES (3, N'Sales') INSERT [Department] ([DepartmentID], [Name]) VALUES (4, N'Marketing') INSERT [Department] ([DepartmentID], [Name]) VALUES (5, N'Finance') GO CREATE TABLE [Employee]( [EmployeeID] [int] NOT NULL PRIMARY KEY, [FirstName] VARCHAR(250) NOT NULL, [LastName] VARCHAR(250) NOT NULL, [DepartmentID] [int] NOT NULL REFERENCES [Department](DepartmentID), ) ON [PRIMARY] GO INSERT [Employee] ([EmployeeID], [FirstName], [LastName], [DepartmentID]) VALUES (1, N'Orlando', N'Gee', 1 ) INSERT [Employee] ([EmployeeID], [FirstName], [LastName], [DepartmentID]) VALUES (2, N'Keith', N'Harris', 2 ) INSERT [Employee] ([EmployeeID], [FirstName], [LastName], [DepartmentID]) VALUES (3, N'Donna', N'Carreras', 3 ) INSERT [Employee] ([EmployeeID], [FirstName], [LastName], [DepartmentID]) VALUES (4, N'Janet', N'Gates', 3 )
SQL Server CROSS APPLY vs INNER JOIN example
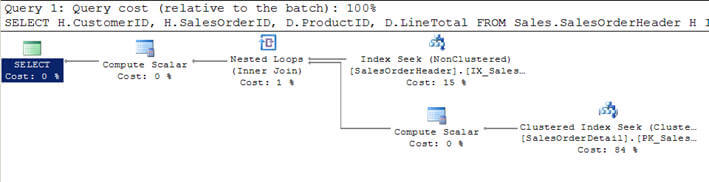
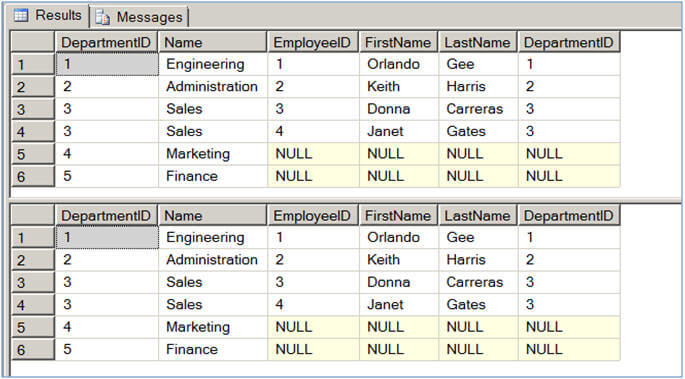
The first query in Script #2 selects data from the Department table and uses a CROSS APPLY to evaluate the Employee table for each record of the Department table. The second query simply joins the Department table with the Employee table and all matching records are produced.
--Script #2 - CROSS APPLY and INNER JOIN SELECT * FROM Department D CROSS APPLY ( SELECT * FROM Employee E WHERE E.DepartmentID = D.DepartmentID ) A GO SELECT * FROM Department D INNER JOIN Employee E ON D.DepartmentID = E.DepartmentID GO
If you look at the results, you can see see they are the same.
Also, the execution plans for these queries are similar and they have an equal query cost, as you can see in the image below.

So what is the use of APPLY operator? How does it differ from a JOIN and how does it help in writing more efficient queries? I will discuss this later.
SQL Sever OUTER APPLY vs LEFT OUTER JOIN example
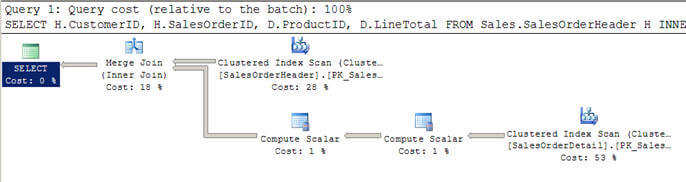
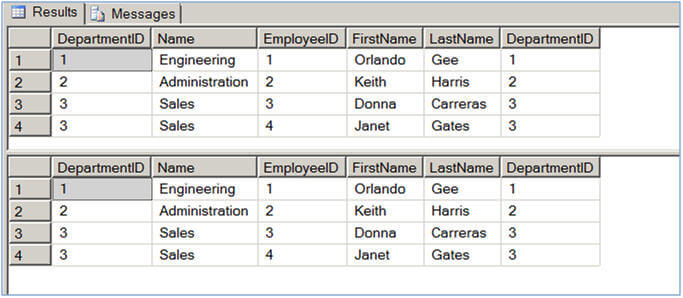
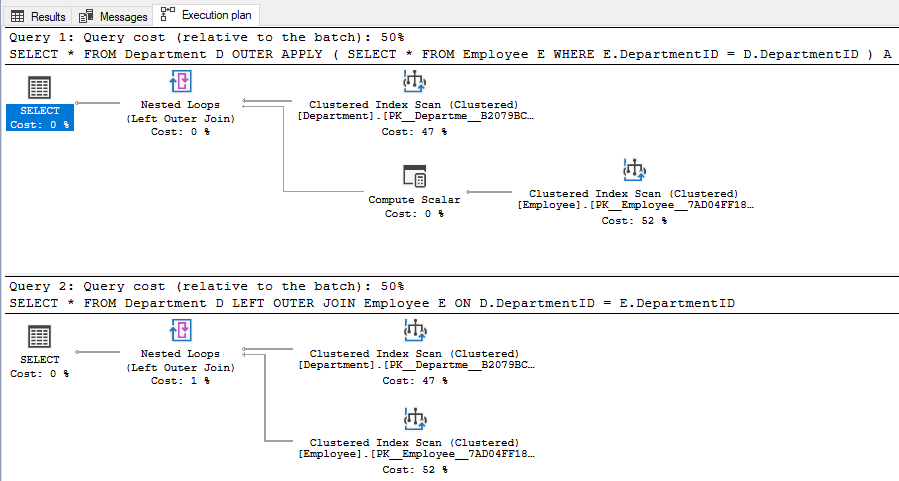
The first query in Script #3 selects data from Department table and uses an OUTER APPLY to evaluate the Employee table for each record of the Department table. For those rows for which there is not a match in the Employee table, those rows contain NULL values as you can see in case of row 5 and 6 below. The second query simply uses a LEFT OUTER JOIN between the Department table and the Employee table. As expected the query returns all rows from Department table, even for those rows for which there is no match in the Employee table.
--Script #3 - OUTER APPLY and LEFT OUTER JOIN SELECT * FROM Department D OUTER APPLY ( SELECT * FROM Employee E WHERE E.DepartmentID = D.DepartmentID ) A GO SELECT * FROM Department D LEFT OUTER JOIN Employee E ON D.DepartmentID = E.DepartmentID GO
Even though the above two queries return the same information, the execution plan is a bit different. Although cost wise there is not much difference, the query with the OUTER APPLY uses a Compute Scalar operator (with estimated operator cost of 0.0000103 or around 0%) before the Nested Loops operator to evaluate and produce the columns of the Employee table.
Joining table valued functions and tables using APPLY operators
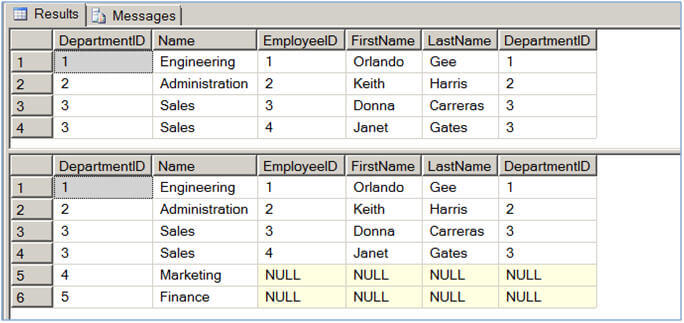
In Script #4, I am creating a table-valued function which accepts DepartmentID as its parameter and returns all the employees who belong to this department. The next query selects data from the Department table and uses a CROSS APPLY to join with the function we created. It passes the DepartmentID for each row from the outer table expression (in our case Department table) and evaluates the function for each row similar to a correlated subquery. The next query uses the OUTER APPLY in place of the CROSS APPLY and hence unlike the CROSS APPLY which returned only correlated data, the OUTER APPLY returns non-correlated data as well, placing NULLs into the missing columns.
--Script #4 - APPLY with table-valued function IF EXISTS (SELECT * FROM sys.objects WHERE OBJECT_ID = OBJECT_ID(N'[fn_GetAllEmployeeOfADepartment]') AND type IN (N'IF')) BEGIN DROP FUNCTION dbo.fn_GetAllEmployeeOfADepartment END GO CREATE FUNCTION dbo.fn_GetAllEmployeeOfADepartment(@DeptID AS INT) RETURNS TABLE AS RETURN ( SELECT * FROM Employee E WHERE E.DepartmentID = @DeptID ) GO SELECT * FROM Department D CROSS APPLY dbo.fn_GetAllEmployeeOfADepartment(D.DepartmentID) GO SELECT * FROM Department D OUTER APPLY dbo.fn_GetAllEmployeeOfADepartment(D.DepartmentID) GO
You might be wondering if we can use a simple join in place of the above queries, the answer is NO. If you replace the CROSS/OUTER APPLY in the above queries with an INNER JOIN/LEFT OUTER JOIN, specifying the ON clause with 1=1 and run the query, you will get the error "The multi-part identifier "D.DepartmentID" could not be bound.". This is because with JOINs the execution context of the outer query is different from the execution context of the function (or a derived table), and you cannot bind a value/variable from the outer query to the function as a parameter. Hence the APPLY operator is required for such queries.
So in summary the APPLY operator is required when you have to use a table-valued function in the query, but it can also be used with inline SELECT statements.
Joining table valued system functions and tables using APPLY operators
Let me show you another query with a Dynamic Management Function (DMF). Script #5 returns all the currently executing user queries except for the queries being executed by the current session. As you can see in the script below, the sys.dm_exec_requests dynamic management view is being CROSS APPLY'ed with the sys.dm_exec_sql_text dynamic management function which accepts a "plan handle" for the query and the "plan handle" is being passed from the left/outer expression to the function to return the data.
--Script #5 - APPLY with Dynamic Management Function (DMF) USE master GO SELECT DB_NAME(r.database_id) AS [Database], st.[text] AS [Query] FROM sys.dm_exec_requests r CROSS APPLY sys.dm_exec_sql_text(r.plan_handle) st WHERE r.session_Id > 50 -- Consider spids for users only, no system spids. AND r.session_Id NOT IN (@@SPID) -- Don't include request from current spid.
Note, for the above query, the [text] column in the query returns all queries submitted in a batch. If you want to see only the active (currently executing) query you can use the statement_start_offset and statement_end_offset columns to trim the active part of the query.