Stored Procedure
A Stored Procedure is nothing more than prepared SQL code that you save so you can reuse the code over and over again. So if you think about a query that you write over and over again, instead of having to write that query each time you would save it as a Stored Procedure and then just call the Stored Procedure to execute the SQL code that you saved as part of the Stored Procedure.
In addition to running the same SQL code over and over again you also have the ability to pass parameters to the Stored Procedure, so depending on what the need is, the Stored Procedure can act accordingly based on the parameter values that were passed.
Stored Procedures can also improve performance. Many tasks are implemented as a series of SQL statements. Conditional logic applied to the results of the first SQL statements determine which subsequent SQL statements are executed. If these SQL statements and conditional logic are written into a Stored Procedure, they become part of a single execution plan on the server. The results do not need to be returned to the client to have the conditional logic applied; all of the work is done on the server.
Benefits of Stored Procedures
- Precompiled execution
SQL Server compiles each Stored Procedure once and then reutilizes the execution plan. This results in tremendous performance boosts when Stored Procedures are called repeatedly.
- Reduced client/server traffic
If network bandwidth is a concern in your environment then you'll be happy to learn that Stored Procedures can reduce long SQL queries to a single line that is transmitted over the wire.
- Efficient reuse of code and programming abstraction
Stored Procedures can be used by multiple users and client programs. If you utilize them in a planned manner then you'll find the development cycle requires less time.
- Enhanced security controls
You can grant users permission to execute a Stored Procedure independently of underlying table permissions.
User Defined Functions
Like functions in programming languages, SQL Server User Defined Functions are routines that accept parameters, perform an action such as a complex calculation, and returns the result of that action as a value. The return value can either be a single scalar value or a result set.
Functions in programming languages are subroutines used to encapsulate frequently performed logic. Any code that must perform the logic incorporated in a function can call the function rather than having to repeat all of the function logic.
SQL Server supports two types of functions
- Built-in functions
Operate as defined in the Transact-SQL Reference and cannot be modified. The functions can be referenced only in Transact-SQL statements using the syntax defined in the Transact-SQL Reference.
- User Defined Functions
Allow you to define your own Transact-SQL functions using the CREATE FUNCTION statement. User Defined Functions use zero or more input parameters, and return a single value. Some User Defined Functions return a single, scalar data value, such as an int, char, or decimal value.
Benefits of User Defined Functions
- They allow modular programming
You can create the function once, store it in the database, and call it any number of times in your program. User Defined Functions can be modified independently of the program source code.
- They allow faster execution
Similar to Stored Procedures, Transact-SQL User Defined Functions reduce the compilation cost of Transact-SQL code by caching the plans and reusing them for repeated executions. This means the user-defined function does not need to be reparsed and reoptimized with each use resulting in much faster execution times. CLR functions offer significant performance advantage over Transact-SQL functions for computational tasks, string manipulation, and business logic. Transact-SQL functions are better suited for data-access intensive logic.
- They can reduce network traffic
An operation that filters data based on some complex constraint that cannot be expressed in a single scalar expression can be expressed as a function. The function can then invoked in the WHERE clause to reduce the number or rows sent to the client.
Differences between Stored Procedure and User Defined Function in SQL Server
| User Defined Function | Stored Procedure |
| Function must return a value. | Stored Procedure may or not return values. |
| Will allow only Select statements, it will not allow us to use DML statements. | Can have select statements as well as DML statements such as insert, update, delete and so on |
| It will allow only input parameters, doesn't support output parameters. | It can have both input and output parameters. |
| It will not allow us to use try-catch blocks. | For exception handling we can use try catch blocks. |
| Transactions are not allowed within functions. | Can use transactions within Stored Procedures. |
| We can use only table variables, it will not allow using temporary tables. | Can use both table variables as well as temporary table in it. |
| Stored Procedures can't be called from a function. | Stored Procedures can call functions. |
| Functions can be called from a select statement. | Procedures can't be called from Select/Where/Having and so on statements. Execute/Exec statement can be used to call/execute Stored Procedure. |
| A UDF can be used in join clause as a result set. | Procedures can't be used in Join clause |
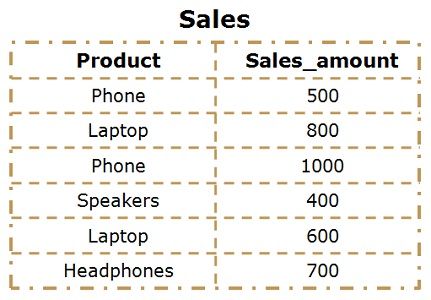 The following query is to be written to calculate the Total_sales of phone and speakers.
The following query is to be written to calculate the Total_sales of phone and speakers. Following output is the resulting output where the rows are filtered first, phone and speaker rows are retrieved then the aggregate function is performed.
Following output is the resulting output where the rows are filtered first, phone and speaker rows are retrieved then the aggregate function is performed.