In this article, I am going to discuss a few tips to improve store procedure performance and give a few points about do's and dont's while writing store procedure in SQL server. To demonstrate a few examples I have chosen an employeedetail table with a few columns like FirstName, LastName, AddressLine1, and Country.
Here in the below snippet, I have written two select statements which are used to fetch records from employeedetail table. The first one is best practices, which means I pick the specific column in the select statement. In the second snippet I have used select * but it is not recommended to use this when fetching records from the table.
SP_StoreProcName is bad practice because when SQL server searches for procedure name then it will first search in the master database then your database. If you prefix with SP_ then it will start looking in system procedures so it will take more time.
If Exists function is used to check if record exists in a table or not. If any records are found then it will return true, else it will return false. One benefit of using If Exists function is that if any match is found then it will stop execution and return true so it will not process the remaining records, so that will save time and improve performance.
In the below example I have used If exists function with select 1 and select *. We should always use select 1 because for the If Exist function it doesn't matter how many records there are; it checks for any record and if it finds one it will return true.
-
-
- Use IF Exists(select 1 from EmployeeDetail where EmployeeId=@EmployeeId)
-
-
- Use IF Exists(select * from EmployeeDetail where EmployeeId=@EmployeeId)
-
Keep your transaction as short as possible
When we are performing multiple inserts, updates or deletes in a single batch it is required to check that all of the operation eigher succeeded or failed. In this situation, we should go for the transaction. When we are using transaction in store procedure that time we need to make sure that transaction should be very small, and it should not block other operations. The length of the transaction affects blocking and sometimes it ends up in a deadlock.
Use try-catch block for error handling
Error handling is a core part of any application. SQL server 2005 and 2008 have a new simple way of handling error using a try-catch block.
- BEGIN TRY
-
- --DML Statement
- --Select Statement
- END TRY
- BEGIN CATCH
-
- END CATCH
Use schema name with object name
Schema name should be used with store procedure name because it will help to compile the plan. It will not search in another schema before deciding to use the cached plan. So always prefix your object with the schema name.
-
- Create procedure [dbo].[usp_GetEmployeeDetails]
- @EmployeeId int
- As
- Begin
- SET NOCOUNT ON
- select FirstName,LastName, AddressLine1, Country from EmployeeDetail where EmployeeId=@EmployeeId
- End
Avoid Null value in fixed length field
We should avoid the Null value in fixed length fields because if we insert the NULL value in a fixed length field, then it will take the same amount of space as the desired input value for that field. So, if we require a null value in a field, then we should use a variable length field that takes lesser space for NULL. The use of NULLs in a database can reduce the database performance, especially, in WHERE clauses. For example, try to use varchar instead of char and nvarchar.
Normalize tables in database
Normalized and managed tables increase the performance of a database. So, always try to perform at least 3rd normal form. It is not necessary that all tables require 3NF normalization form, but if any table contains 3NF form normalization, then it can be called well structured tables.
Keep Clustered Index Small
Clustered index stores data physically into memory. If the size of a clustered index is very large, then it can reduce the performance. Hence, a large clustered index on a table with a large number of rows increases the size significantly. Never use an index for frequently changed data because when any change in the table occurs, the index is also modified, and that can degrade performance.
Use Appropriate Datatype
If we select inappropriate data type, it will reduce the space and enhance the performance; otherwise, it generates the worst effect. So, select an appropriate data type according to the requirement. SQL contains many data types that can store the same type of data but you should select an appropriate data type because each data type has some limitations and advantages upon another one.
Store image path instead of image itself
I found that many developers try to store the image into database instead of the image path. It may be possible that it is requirement of application to store images into database. But generally, we should use image path, because storing image into database increases the database size and reduces the performance.
USE Common Table Expressions (CTEs) instead of Temp table
We should prefer a CTE over the temp table because temp tables are stored physically in a TempDB which is deleted after the session ends. While CTEs are created within memory. Execution of a CTE is very fast as compared to the temp tables and very lightweight too.
Use Appropriate Naming Convention
The main goal of adopting a naming convention for database objects is to make it easily identifiable by the users, its type, and purpose of all objects contained in the database. A good naming convention decreases the time required in searching for an object. A good name clearly indicates the action name of any object that it will perform.
- * tblEmployees // Name of table
- * vw_ProductDetails // Name of View
- * PK_Employees // Name of Primary Key
Use UNION ALL instead of UNION
We should prefer UNION ALL instead of UNION because UNION always performs sorting that increases the time. Also, UNION can't work with text datatype because text datatype doesn't support sorting. So, in that case, UNION can't be used. Thus, always prefer UNION All.
Use Small data type for Index
It is very important to use Small data type for index. Because, the bigger size of data type reduces the performance of Index. For example, nvarhcar(10) uses 20 bytes of data and varchar(10) uses 10 bytes of the data. So, the index for varhcar data type works better. We can also take another example of datetime and int. Datetime data type takes 8 Bytes and int takes 4 bytes. Small datatype means less I/O overhead that increases the performance of the index.
- Use Count(1) instead of Count(*) and Count(Column_Name):
There is no difference in the performance of these three expressions; but, the last two expressions are not well considered to be a good practice. So, always use count(10) to get the numbers of records from a table.
Use Stored Procedure
Instead of using the row query, we should use the stored procedure because stored procedures are fast and easy to maintain for security and large queries.
Use Between instead of In
If Between can be used instead of IN, then always prefer Between. For example, you are searching for an employee whose id is either 101, 102, 103 or 104. Then, you can write the query using the In operator like this:
- Select * From Employee Where EmpId In (101,102,103,104)
You can also use Between operator for the same query.
- Select * from Employee Where EmpId Between 101 And 104
Use Foreign Key with appropriate action
A foreign key is a column or combination of columns that is the same as the primary key, but in a different table. Foreign keys are used to define a relationship and enforce integrity between two tables. In addition to protecting the integrity of our data, FK constraints also help document the relationships between our tables within the database itself. Also define an action rule for delete and update command, you can select any action among the No Action, Set NULL, Cascade and set default.
Use Alias Name
Aliasing renames a table or a column temporarily by giving another name. The use of table aliases means to rename a table in a specific
SQL statement. Using aliasing, we can provide a small name to large name that will save our time.
Drop Index before Bulk Insertion of Data
We should drop the index before insertion of a large amount of data. This makes the insert statement run faster. Once the inserts are completed, you can recreate the index again.
Use Unique Constraint and Check Constraint
A Check constraint checks for a specific condition before inserting data into a table. If the data passes all the Check constraints then the data will be inserted into the table otherwise the data for insertion will be discarded. The CHECK constraint ensures that all values in a column satisfies certain conditions.
A Unique Constraint ensures that each row for a column must have a unique value. It is like a Primary key but it can accept only one null value. In a table one or more column can contain a Unique Constraint. So we should use a Check Constraint and Unique Constraint because it maintains the integrity in the database.
Importance of Column Order in index
If we are creating a Non-Clustered index on more than one column then we should consider the sequence of the columns. The order or position of a column in an index also plays a vital role in improving SQL query performance. An index can help to improve the SQL query performance if the criteria of the query matches the columns that are left most in the index key. So we should place the most selective column at left most side of a non-clustered index.
Recompiled Stored Procedure
We all know that Stored Procedures execute T-SQL statements in less time than the similar set of T-SQL statements are executed individually. The reason is that the query execution plan for the Stored Procedures are already stored in the "sys.procedures" system-defined view. We all know that recompilation of a Stored Procedure reduces SQL performance. But in some cases it requires recompilation of the Stored Procedure. Dropping and altering of a column, index and/or trigger of a table. Updating the statistics used by the execution plan of the Stored Procedure. Altering the procedure will cause the SQL Server to create a new execution plan.
Use Sparse Column
Sparse column provide better performance for NULL and Zero data. If you have any column that contain large amount numbers of NULL and Zero then prefer Sparse Column instead of default column of SQL Server. Sparse column take lesser space then regular column (without SPARSE clause).
Example
- Create Table Table_Name
- (
- Id int, //Default Column
- Group_Id int Sparse // Sparse Column
- )
Avoid Loops In Coding
Suppose you want to insert 10 of records into table then instead of using a loop to insert the data into table you can insert all data using single insert query.
- declare @int int;
- set @int=1;
- while @int<=10
- begin
- Insert Into Tab values(@int,'Value'+@int);
- set @int=@int+1;
- end
Above method is not a good approach to insert the multiple records instead of this you can use another method like below.
- Insert Into Tab values(1,'Value1'),(2,'Value2'),(3,'Value3'),(4,'Value4'),(5,'Value5'),(6,'Value6'),(7,'Value7'),(8,'Value8'),(9,'Value9'),(10,'Value10');
Avoid Correlated Queries
In A Correlated query inner query take input from outer(parent) query, this query run for each row that reduces the performance of database.
- Select Name, City, (Select Company_Name
- from
- Company where companyId=cs.CustomerId) from Customer cs
The best method is that we should prefer the join instead of correlated query as below.
- Select cs.Name, cs.City, co.Company_Name
- from Customer cs
- Join
- Company co
- on
- cs.CustomerId=co.CustomerId
Avoid index and join hints
In some cases, index and join hint may increase the performance of database, but if you provide any join or index hint then server always try to use the hint provided by you although it has a better execution plan, so such type of approach may reduce the database performance. Use Join or index hint if you are confident that there is not any better execution plan. If you have any doubt then make server free to choose an execution plan.
Avoid Use of Temp table
Avoid use of temp table as much as you can because temp table is created into temp database like any basic table structure. After completion of the task, we require to drop the temp table. That rises the load on database. You can prefer the table variable instead of this.
Use Index for required columns
Index should be created for all columns which are using Where, Group By, Order By, Top, and Distinct command.
Don't use Index
It is true that use of index makes the fast retrieval of the result. But, it is not always true. In some cases, the use of index doesn't affect the performance of the query. In such cases, we can avoid the use of index.
- When size of table is very small.
- Index is not used in query optimizer
- DML(insert, Update, Delete) operation are frequent used.
- Column contain TEXT, nText type of data.
Use View for complex queries
If you are using join on two or more tables and the result of queries is frequently used, then it will be better to make a View that will contain the result of the complex query. Now, you can use this View multiple times, so that you don't have to execute the query multiple times to get the same result.
Use Full-text Index
If your query contains multiple wild card searches using LIKE(%%), then use of Full-text Index can increase the performance. Full-text queries can include simple words and phrases or multiple forms of a word or phrase. A full-text query returns any document that contains at least one match (also known as a hit). A match occurs when a target document contains all the terms specified in the Full-text query, and meets any other search conditions, such as the distance between the matching terms.
In the first procedure, I have not used SET NOCOUNT ON statement so it has printed a message for how many rows are affected. It means if we do not use this then it will print an extra message and it affects performance.
-
- Create procedure [dbo].[usp_GetEmployeeDetails]
- @EmployeeId int
- As
- Begin
-
- select FirstName,LastName, AddressLine1, Contry from EmployeeDetail
- End
In the below procedure, I have user SET NOCOUNT ON so it is not returning the how many rows are affected message. This message doesn't matter for limited numbers of records but when we are dealing with a large number of records it matters a lot. So always use SET NOCOUNT ON statement at the top of your store procedure.
-
- CREATE procedure [dbo].[usp_GetEmployeeDetails]
- As
- Begin
- SET NOCOUNT ON
- select FirstName,LastName, AddressLine1, Contry from EmployeeDetail where Contry ='Ind'
- End
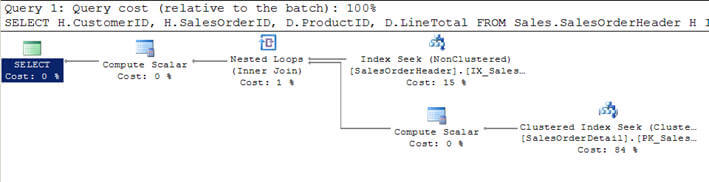
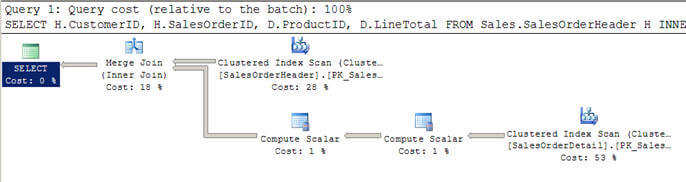
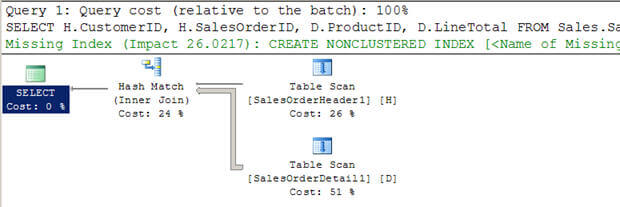
Use the Primary key & Index properly in the table
It is good practice to use primary key for each table and indexes in appropriate scenarios. It will speed up retrieving and searching records from the database. Here we have three snippets to understand a few points about how select statement works in different scenarios.
In the first screen I have used table Employee1 where I do not have a primary key for the table and I have to tried to retrieve data from the table, then perform the table scan.
In the second screen I have another table, EmployeeDetail, which has primary key EmployeeId and I have tried to retrieve all data from employee table but it performs Index scan because it has the primary key. So it's good to have a primary key for each table. If you create a primary key on column it will create a cluster index on that column. Index scan is better than the table scan.
In the below screen, you can see I have a primary key column and I have used a primary key cloumn in the where clause, so it is performing Index scan which is better than the above two in performance.
A few more points we can keep in mind while writting store procedure:
- While writing store procedure avoid aggregate function in where clause because it reduces performance.
- Try to write program logic in the business layer of the application not in store procedure.
- Try to avoid cursor inside procedure if it is possible.
- Try to avoid DDL operation in store procedure because DDL operation may change execution plan so SP can not reuse the same plan.